
CHAPTER 20
How The Internet Works
TIME LIMIT: 2 HOURS
What happens when you type google.com into your browser’s address box and press enter?
- A popular interview question
It’s good to take a step back occasionally and think about what you are doing. In Part 2, we made a few webpages and then served them over the Internet… but what is actually happening there? How do webpages show up in our browsers?
This chapter begins to peel this question like an onion. It introduces you to some of the basic networking principles that underlay the Internet.
1. Webpages are just HTML, CSS, and JavaScript files that have been shared from someone else’s computer to yours. That’s it.
Webpages are made out of four general types of files: HTML, CSS, JavaScript, and digital assets.
HTML provides the structure of webpages. All of the content you see on the page - text, images, forms - is identified using HTML tags. The DIV tag is an especially handy container.

CSS is for styling the content. Positioning on the pages, colors, fonts, backgrounds… all of these come from CSS. CSS declarations identify content using the HTML tags and attributes (e.g. classes and IDs), then styles those tags.
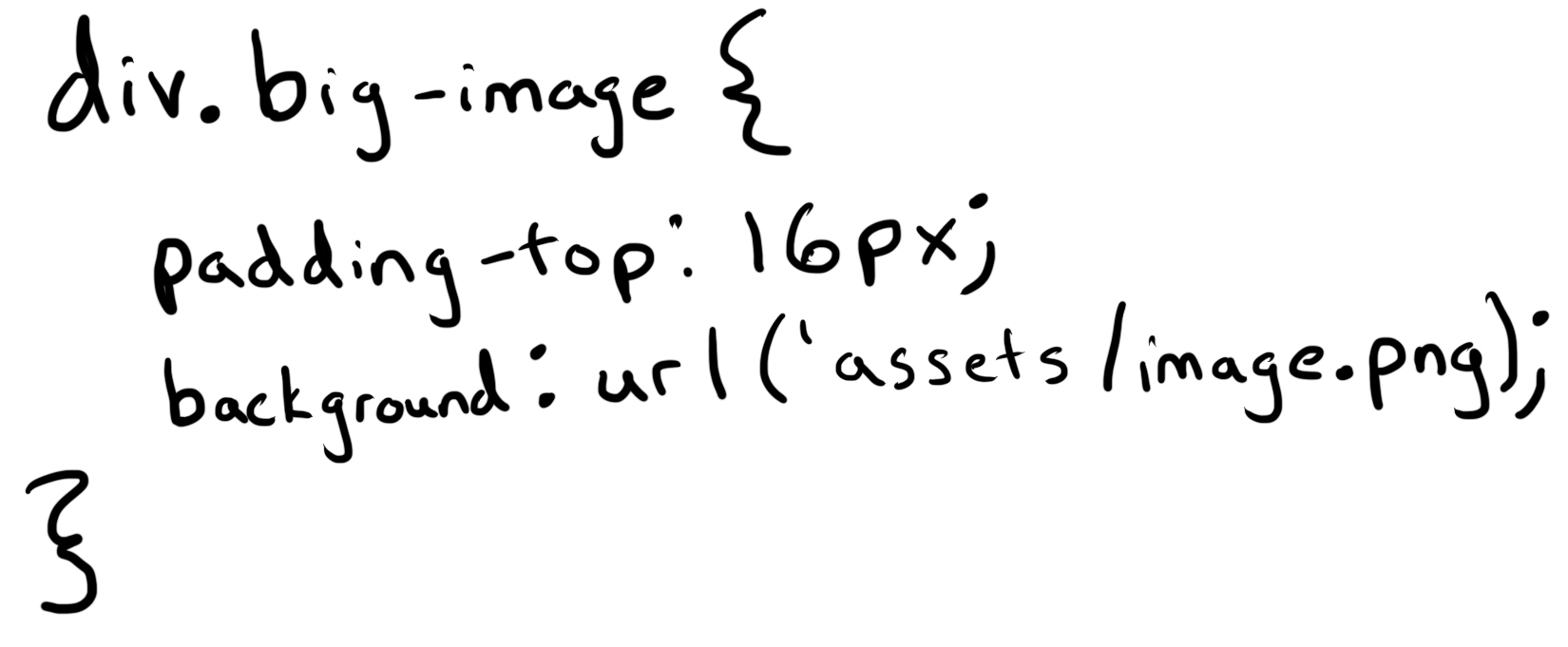
JavaScript is for user interactivity. When a user clicks a button or submits a form, whatever happens next is generally being handled by JavaScript.

Digital assets are everything else: Picture files, data files, etc.

This is why front-end developers spend most of their time working with HTML, CSS, and JavaScript. They are the three programming languages that all browsers understand.
2. OK, so how do these code files move from someone else’s computer to my browser? The Client-Server Model.
A browser requesting a webpage is a classic example of what is known as the client-server model. Client computers (browsers) ask for files. Server computers serve those files back.
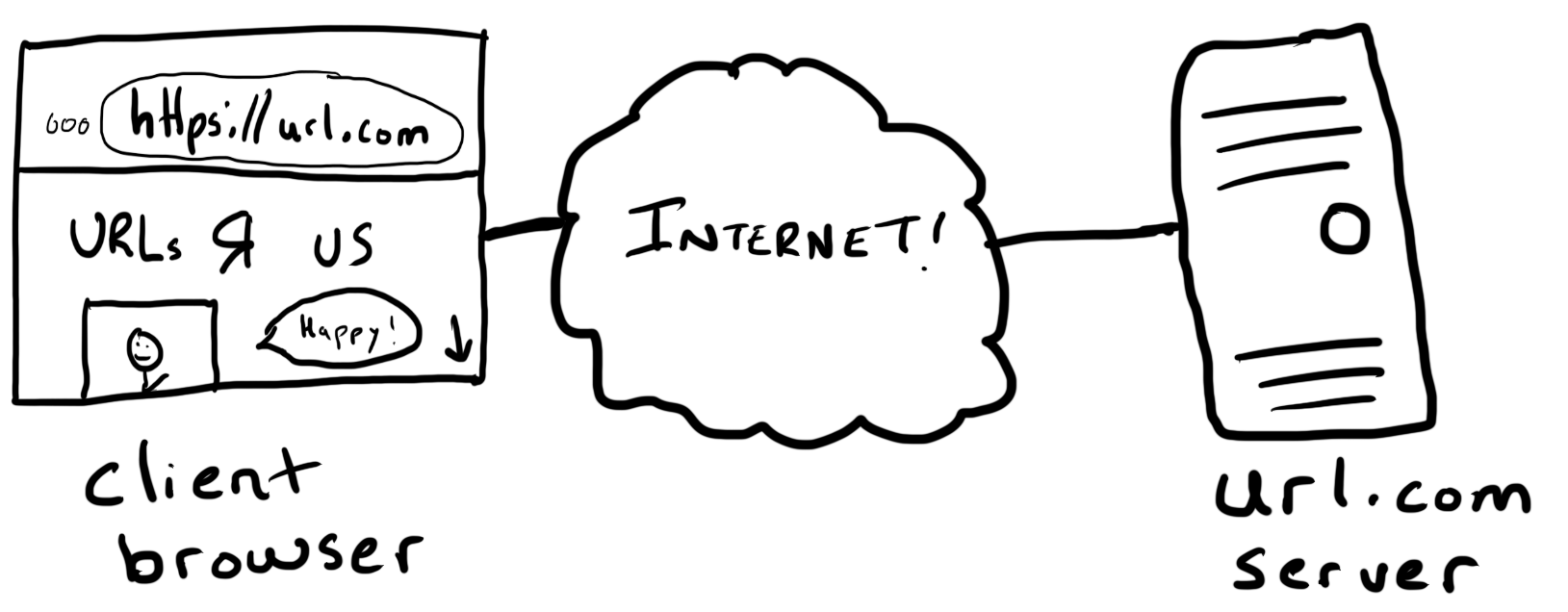
We see three players in action here.
The client. A client browser requests a resource using it’s Uniform Resource Locator, e.g. https://url.com.
The server. An Internet-connected computer is listening at url.com and is ready to serve up those resources. The server appliction processes the request, then sends a response back. The response is made up of HTML, CSS, JavaScript, image, data, and/or other resources.
The Internet. The Internet is the computer network over which these requests and responses travel. This network has its own set of rules and infrastructure.
3. The Request-Response Cycle
This pattern of requests and responses is common in client-server architectures. It has an unsurprising name: the request-response cycle.
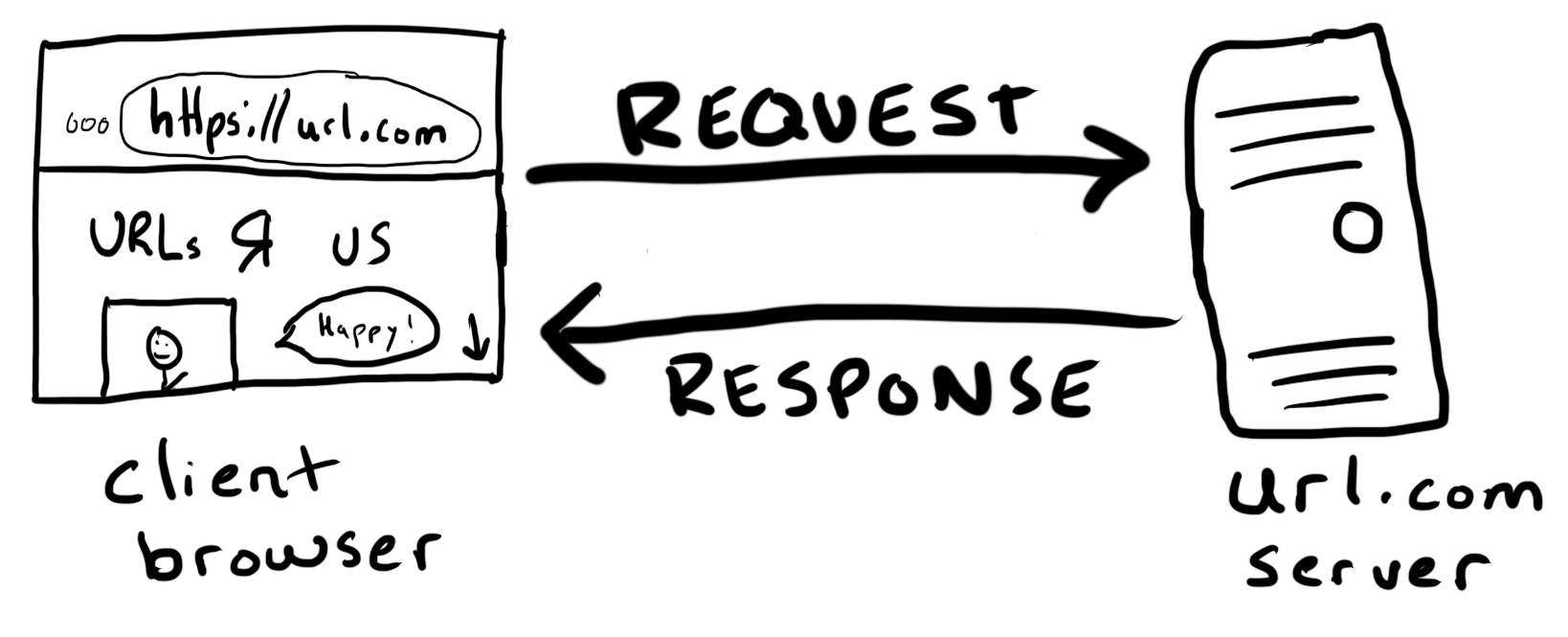
The Internet has transmitted an extraordinarily number of these requests and responses over the last 30 years. Billions (trillions?) of different kinds of devices and software applications have communicated over the Internet using the request-response cycle.
Given the obvious differences between such communicating devices and applications, the need for a standardized messaging protocol arises. To communicate, computers must have a standardized language they can speak together. Two computers can only reliably talk to each other when they agree on a standardized set of rules to talk to each other - a communications protocol.
4. HyperText Transfer Protocol - How Infinite Kinds of Devices Talk to Each Other Over The Internet.
All of these responses and requests use a messaging protocol known as HyperText Transfer Protocol, or HTTP. That is what the “http” is at the beginning of a URL stands for. HTTPS stands for Secure HTTP.
The web runs on HTTP messaging.
In HTTP messaging, everything is either a request or a response. Messages are divided into two parts, headers and the body.
Headers are mandatory and contain “metadata”. Metadata includes things like the host name (e.g. google.com), the specific resource path (the default path is / ), and the kind of data the client wants back in any response message body (e.g. text/html or application/json). It makes sense that headers are mandatory – where will the message go if you don’t say what host you want?
Message bodies are optional. Bodies contain whatever other data somebody wants to sent around. HTML, CSS, JS, and images are all data and get sent in the message body.
An example will help clarify. You will never have to write out raw HTTP messages (I hope), but this is what they look like:
HTTP Requests
An HTTP request to GET google.com’s homepage looks like this:
GET / HTTPS/1.1
User-Agent: Mozilla/4.0
Host: www.google.com
Accept-Language: en-us
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Clients originate HTTP requests when they want something from an external server computer. In the case of typing in google.com and hitting enter, your browser is saying “Hey server located at Google.com, please give me the resource located at /”.
There is no message body in this particular “GET request, only headers. See the first header in the request -GET / HTTPS/1.1? GET is the request verb and / is the requested resource (remember, this is the default). Now look at the third line of the request - www.google.com is the host. See the exercises (or check Mozilla!) to learn more about how URLs get translated into HTTP requests.
HTTP Responses
The Google.com server’s HTTP response will look something like this:
HTTPS/1.1 200 OK
Date: Mon, 27 Jul 2018 12:28:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2018 19:15:56 GMT
Content-Type: text/html; charset=UTF-8
Connection: Closed
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta content="Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for." name="description"><meta content="noodp" name="robots"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><link href="/images/branding/product/ico/googleg_lodp.ico" rel="shortcut icon"><meta content="origin" name="referrer"><title>Google</title>
....the HTML goes on
This HTTP response includes both a header and a body, separated by a blank line. This is the “protocol” part of HTTP. That blank line tells your computer “Hey, we’re done sending headers, anything that comes after this is body data.”
HTTP response headers always include what is known as a status code. Status codes are numbers that tell you things like, “Everything is good, here is what you want” (200) and “I don’t know who you are, so I can’t help” (401) and “I know who you are, but I’m not giving you this” (403).
Once a browser loads the initial HTML file from the first URL request, that HTML file contain code that makes the browser to make dozens, hundreds, or even thousands more HTTP requests to various servers. Thus one HTML page can tell the browser to go get all of the other kinds of CSS, JavaScript, and digital asset files it needs.
You can see this happening with the Network developer tool. Try loading your favorite webpages with it and see what sorts of requests they’re sending? If you do not use an ad blocker in your browser, you will be shocked by how much advertising data is being collected from your browser.
5. Don’t lose sight of the fact that the real value a web engineer delivers is a working webpage to end users.
It’s great to cultivate knowledge about networking. However, there is only so much you need to know at first, and it is mostly covered by this chapter and its exercises. Don’t get too lost chasing the networking dragon. Your primary job is to write HTML, CSS, and JavaScript right now.
Conclusion: The Internet is just a bunch of computers talking to each other.
The Internet is a bunch of computers exchanging electronic requests and responses for code files and assets, mostly using HTTP protocol. There are other messaging protocols (e.g. File Transfer Protocol AKA FTP), but you don’t need to worry about those right now.
Exercises
-
What are three programming languages all browsers can read?
-
Go read this article and use it to help answer the next several questions. “HTTP: The Protocol Every Web Developer Must Know - Part 1” - https://code.tutsplus.com/tutorials/http-the-protocol-every-web-developer-must-know-part-1–net-31177
-
How are URLs structured? Describe what each of the following is: protocol, host, port, resource path, and query.
-
GET, POST, PUT, and DELETE are the four most common HTTP request verbs. What does each of these do?
-
HTTP response codes AKA status codes convey important information back to the browser. What do the status codes 200, 301, 304, 400, 401, 404, 503 communicate?
-
Open the Network developer tool in your favorite browser. Visit 5 of your favorite pages and watch all of the requests load. Click on some of the requests. Can you find the status codes?
-
IMPORTANT! In the Netork developer tool: Do you see a “Disable cache” option? That’s a good box to check when you’re developing, so that the code you’re working actually reloads fresh each time.
Skim this article about web caching and why you want to disable the cache. https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-caching
-
It’s good to have a few “How Does This Whole Internet/World Wide Web/Webpage/Browser Thing Work Anyway” papers in your knowledge arsenal. Here are some of my favorites. Skim at least one of them.
- https://en.wikipedia.org/wiki/Internet
- https://web.stanford.edu/class/msande91si/www-spr04/readings/week1/InternetWhitepaper.htm
- https://en.wikipedia.org/wiki/Client%E2%80%93server_model
- https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/
- Star this repo for future reference: https://github.com/alex/what-happens-when
- https://medium.com/@maneesha.wijesinghe1/what-happens-when-you-type-an-url-in-the-browser-and-press-enter-bb0aa2449c1a
-
OK, so all are these computers are connected and communicated by HTTP… but how do they find each other? Enter the Domain Name System (DNS). https://hacks.mozilla.org/2018/05/a-cartoon-intro-to-dns-over-https/
-
Here’s a question to chew on: What’s the difference between the Internet and World Wide Web?
-
Is “cloud computing” really just a giant warehouse of computers with an internet connection?
Yes. Those warehouses are called “data centers”. They all have really great air conditioning centers to keep the computers from overheating. 🔥